





La librería Amazon ha añadido una pequeña funcionalidad a su extraordinaria sección Search Inside (que permite leer y buscar en el contenido completo de los libros a través del navegador). Se llama Text Stats y es una recopilación estadística sobre las palabras contenidas en los libros, algo bastante curioso a la vez que útil.
Por ejemplo, para Innumeracy (El Hombre Anumérico) de John Allen Paulos:

Los datos incluyen el número de caracteres, palabras y frases. Los indicadores complejidad calculan el número de palabras por frase y sílabas por palabra, además del número de «palabras complicadas» (de más de tres sílabas). Unos indicadores de legibilidad aplican ciertos índices que señalan cómo de fácil es leer el libro para una persona: cuántos años de educación normal se necesitan (Fog/Flesch-Kincaid) o cómo de «fácil» de 0 a 100 es de leer (siendo 100 es el más fácil). Además de esto se calculan los percentiles de cada uno de estos valores respecto a otros libros, ya sean de la misma categoría o en general.
También hay una nube de palabras según su frecuencia en el texto. Esta sería por ejemplo la de Cosmos, de Carl Sagan:
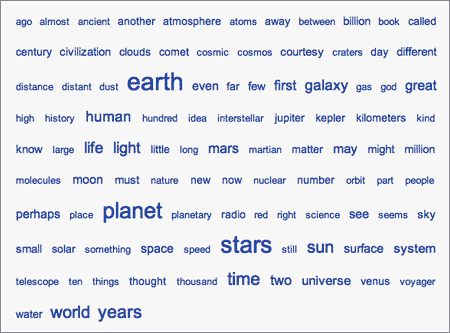
En esta lista alfabética de concordancia se eliminan las palabras más comunes (stop words) que resultarían muy aburridas de examinar. Pasando el ratón por encima de cada palabra se ve el número de veces que aparece en el libro. Según esto, Sagan usó su famoso «billón» exactamente 162 veces en las páginas de su obra.
La diversión culmina con el dato de cuántas palabras por dólar (o por onza de peso) proporciona el libro.
(Vía al 98,5% desde information aesthetics.)

